阿里云NLP平台技术文档——短文本匹配
短文本匹配:上传短文本匹配数据,训练短文本语义匹配模型,使用模型时,输入两个短文本,返回相似度
NLP自学习平台使用流程如下图所示:
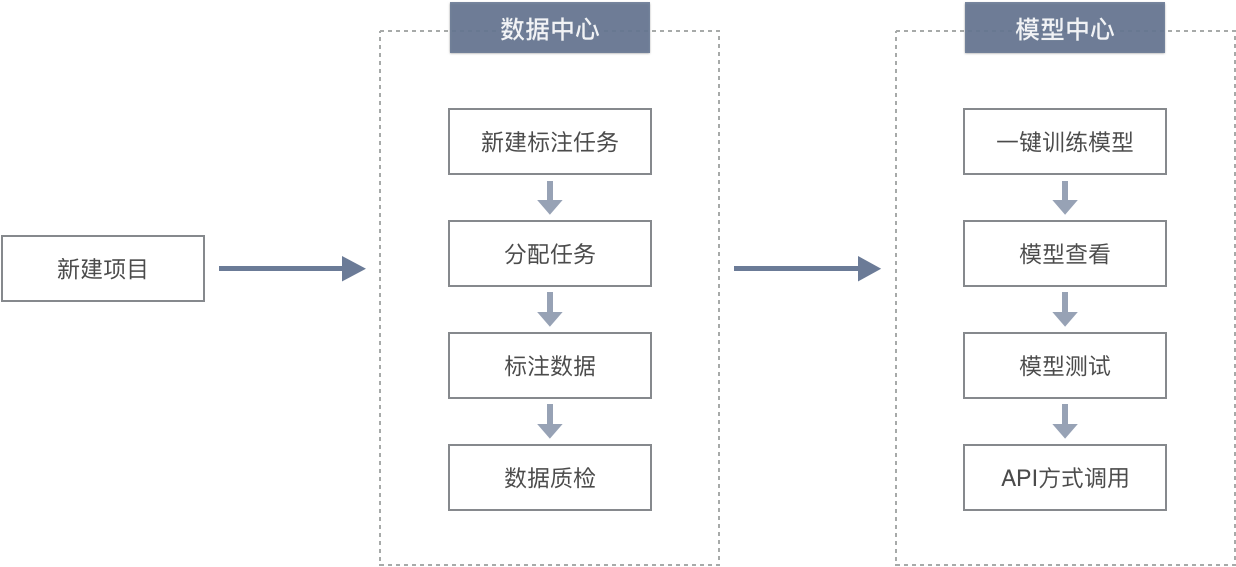
实现短文本匹配步骤:
步骤一:创建项目
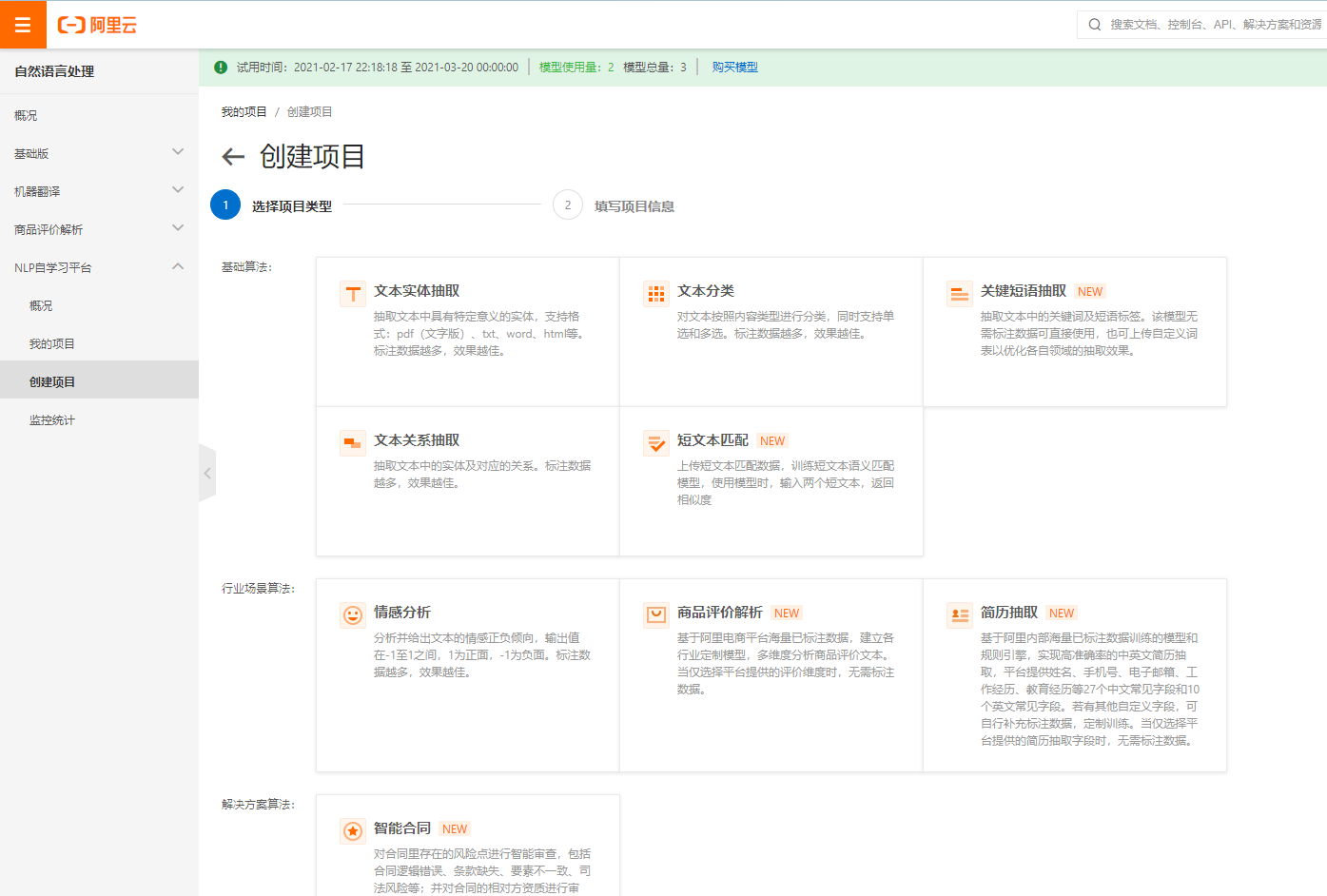
创建并管理自己的项目,目前您可以创建八种项目类型:1、文本实体抽取;2、文本分类;3、关键短语抽取;4、情感分析;5、关系抽取;6、短文本匹配;7、商品评价解析;8、简历抽取
注意:项目可添加更多的项目管理员,管理员拥有这个项目下所有权限(项目、数据、模型等),通过输入阿里云账号添加;同时,也支持子账号管理项目
搜索自然语言处理/NLP,点击左侧工具栏的“创建项目”,选择所需项目类型,这里以短文本匹配为例,点击“短文本匹配”
步骤二:数据管理
2.1创建标注任务
1、上传代标注文档,添加标注人员
进入某一项目后,可以在数据中心中管理您的数据,有两种方式可以创建数据:1、创建标注任务;2、上传数据集。
填写项目信息
打*号为必填项,填写项目类型,项目名称,项目描述。“行业类型”填写最相近的行业类型,管理员会定期针对性地优化行业语言模型,准确的行业类型将有助于提高模型准确率。
填写完毕后,点击确认。
注意:创建者和项目管理员默认为标注人员,同时,您也可以将标注任务分配给您创建的阿里云子账号,被分配用户通过子账号的账号密码登录本平台,即可参与数据标注。子账号登录说明:1、子账号登录页,登录:https://signin.aliyun.com/login.htm2、登录后,复制该URL进入标注页面:https://nlp-automl.aliyun.com/automl/annotation/index

步骤二:设置待标注的题目
不同项目类型中的题目类型会有所不同,例如文本实体抽取项目中的题目为实体名:
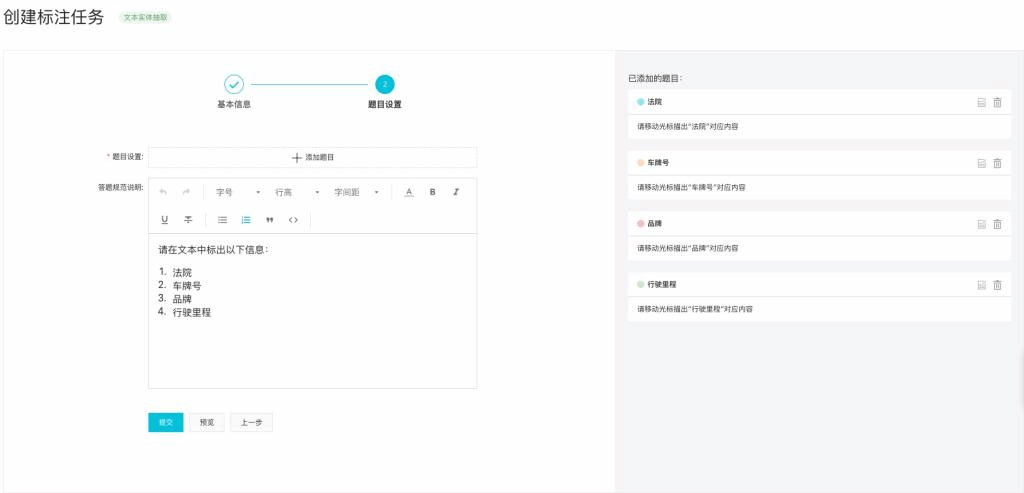
文本分类项目中的题目为分类名:

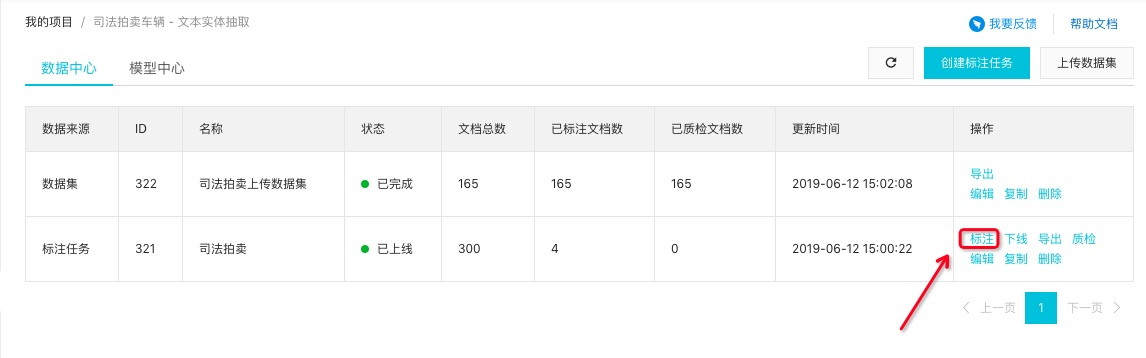
步骤三:标注数据
完成标注任务的创建后,您可以在数据中心中,点击标注进入标注中心,进行文档的标注,每篇文档仅会被标注一次
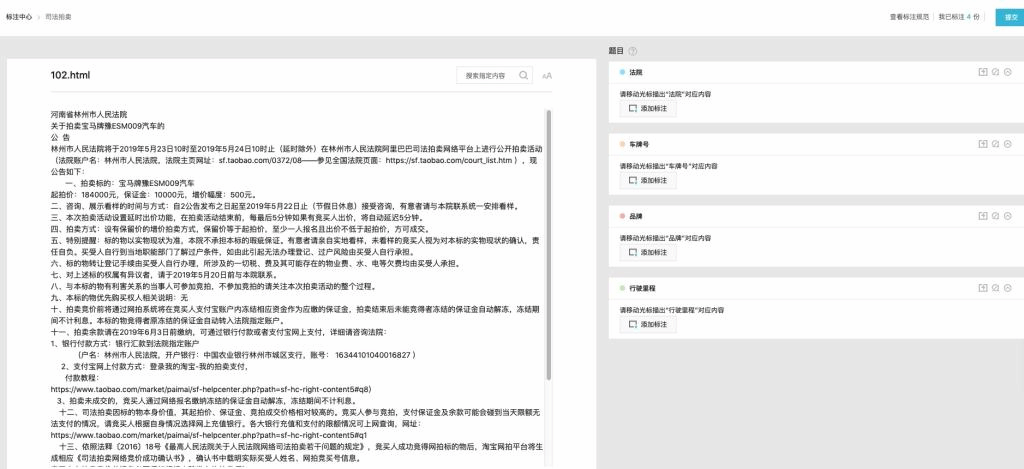
步骤四:数据质检(可选)
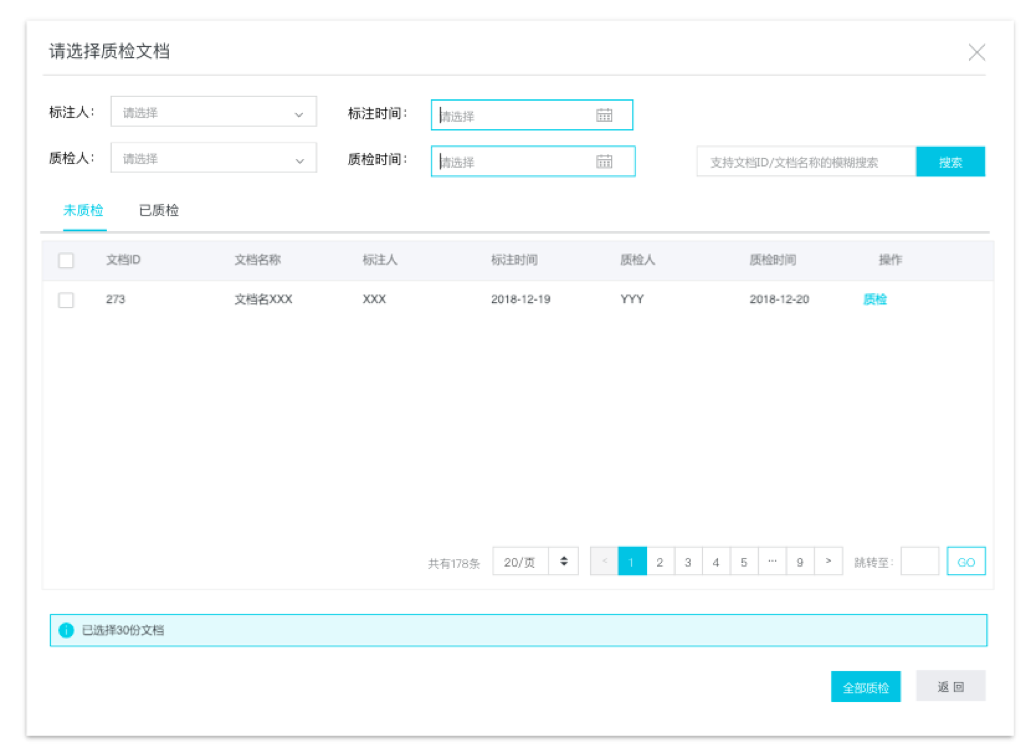
您可以通过筛选和搜索,质检已经标注好的文档,以确保良好的标注质量
2.2 上传数据集
除了创建标注任务外,您也可以上传本地已标注好的训练数据,按示例文件的格式规整后,直接上传

1、点击进入项目

2、点击创建标注项目

填写相关信息,填写任务名称,并上传数据文件,点击提交。
注意:数据文件类型仅支持.txt,.xlsx格式,一次最多可上传200个文件,单个文件大小不超过20M。
添加的标注数据至少要500个以上,且要包含相似和不相似的文本。数据越多,相似和不相似的越多,相似度越高。

3、进入该页面,若一直在解析中,可以点击右上角的更新按钮,进行更新
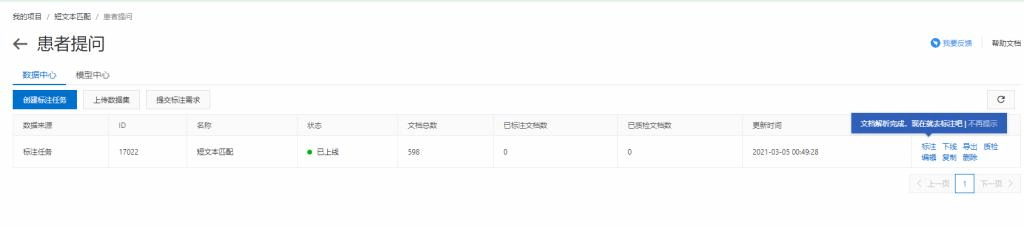
4、点击标注,进入标注页面,进行标注
5、标注完成后,点击模型中心,开始训练模型,点击“训练”
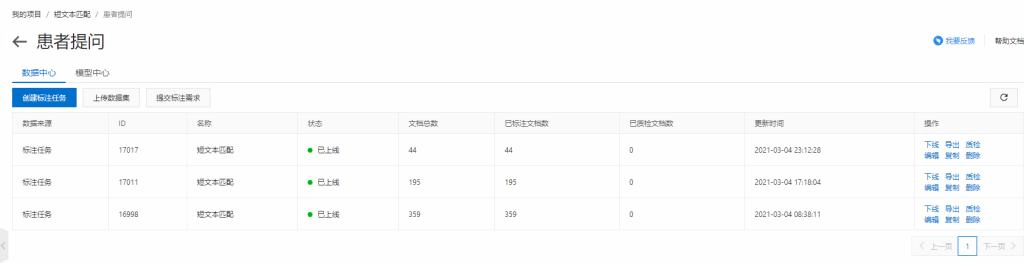
6、训练完成后,显示如下表示训练完成

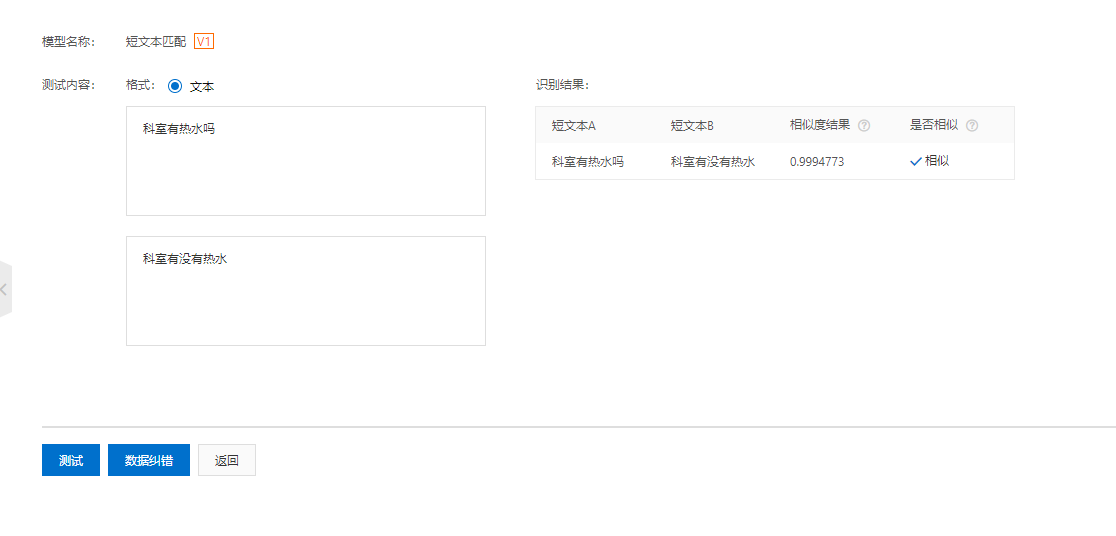
7、现在可以进行测试,测试模型是否正确。输入两个数据,测试内容是否相似。此时如果发现测试错误,则进行数据纠错。纠正的数据将自动保存在“短文本匹配V1”数据集中,之后可以补充该数据集,新增版本重新训练模型。
三、 模型管理
用户可以在模型中心中一键训练模型,查看模型评估指标,并进行在线可交互测试,测试完毕后可通过API方式调用接口
步骤一:训练模型
在创建模型页中,输入模型基本信息,选择已标注完的数据,一键训练模型,模型训练需0.5-1小时
步骤二:模型查看
您可以查看模型的相关评估指标,主要有精确率、召回率和F1值;同时,您也可以新增模型版本,进行版本管理
注意:如果训练数据在100份以内,模型效果可能欠佳,且评估指标波动较大,基本无参考意义。若需要良好稳定的模型效果,训练数据建议在500份以上
步骤三:模型测试
模型发布后,您可以直接在平台上进行测试,并对不准的预测结果进行纠错
注意:为方便业务使用,同一模型同时可以发布两个版本,若需发布第三个版本,请手动下线一个已发布的版本
步骤四:API调用模型

